Infrastructure as Code : Kubernetes en quelques minutes avec Terraform et Ansible
Automatisez le déploiement de votre cluster Kubernetes de A à Z ! Découvrez comment combiner la puissance de Terraform et la flexibilité d’Ansible pour créer une infrastructure cloud scalable et un cluster Kubernetes opérationnel en quelques commandes. Un guide pratique pour accélérer vos déploiements DevOps.
Code source
Playbook Ansible : ici
Code terraform : ici
Le main.tf :
locals {
debian_vms = {
master-00 = { vm_id = 501, ip = "172.16.20.30/24" }
master-01 = { vm_id = 502, ip = "172.16.20.31/24" }
master-02 = { vm_id = 503, ip = "172.16.20.32/24" }
worker-00 = { vm_id = 504, ip = "172.16.20.33/24" }
worker-01 = { vm_id = 505, ip = "172.16.20.34/24" }
worker-02 = { vm_id = 506, ip = "172.16.20.35/24" }
}
}
module "debian_vm" {
for_each = local.debian_vms
source = "./modules/debian-bookworm-datastore"
vm_id = each.value.vm_id
vm_name = each.key
node_name = "pve"
datastore_id = "DATASTORE"
disk_size = 30
memory = 8192
cpu_cores = 4
ipv4_address = each.value.ip
gateway = "172.16.20.254"
ssh_public_key_path = "public_keys/bastion.pub"
}
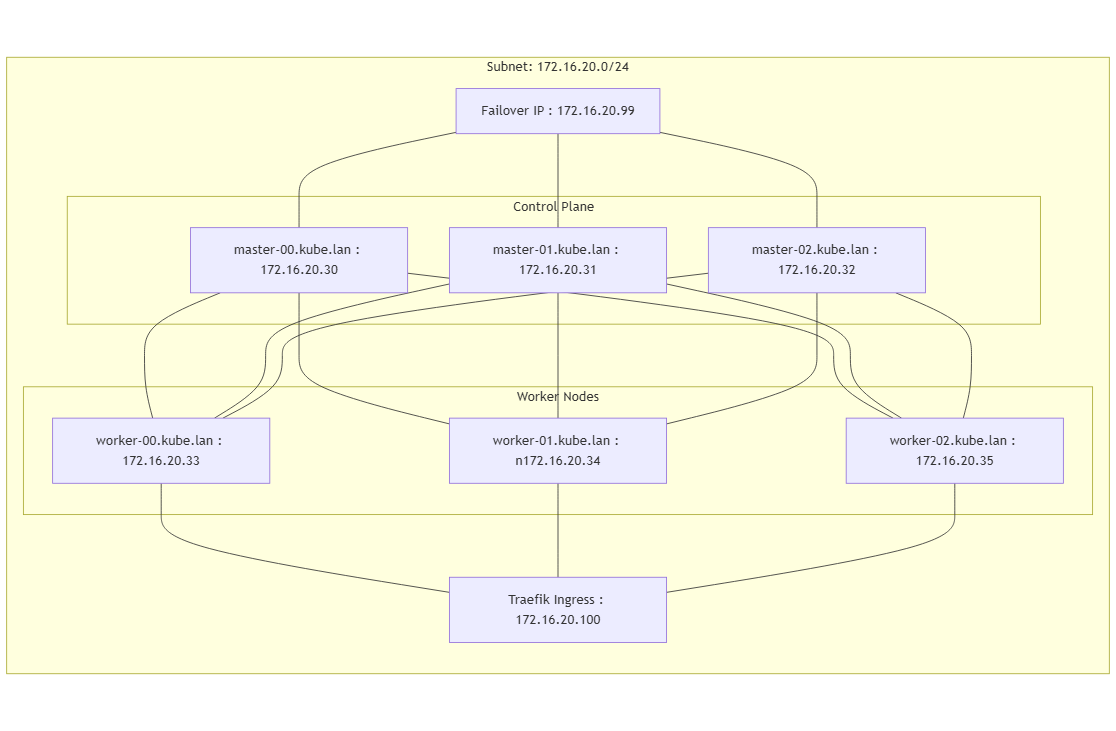
Architecture
Dimensionnement
Pour un cluster "Production Ready" sans stockage HA... :
- 6 VM (4vCPU, 8Go RAM, Stockage 20Go pour du PoC)
Pour un PoC (master - worker) :
- 2 VM (4vCPU, 8Go RAM, Stockage 20Go pour du PoC)
Pour un PoC - ressources faibles :
- 2 VM (2vCPU, 4Go RAM, 20Go pour du PoC)
Peut être "ric rac" au niveau de la RAM.
Plan d'addressage
- Il faudra une @IP par nœud.
- Il faudra une @IP dédiée à la VIP (IP Failover), qui servira à accéder au control-plan.
- Il faudra une @IP dédiée à l'Ingress Traefik, qui permettra de créer des règles (host, vpath) pour exposer des pods vers l'extérieur.
Avant exécution - mise à jour plan addressage
Il faudra définir dans votre plan réseau une VIP, par exemple dans 172.16.20.0/24, avec une VIP à 172.16.20.99, qui permettra d'accéder au control-plan.
Si le plan d'adressage/et ou la VIP est différents :
Éditez les fichiers suivants :
roles/keepalived/templates/backup.cfgroles/keepalived/templates/master.cfg
Au niveau de :
virtual_ipaddress {
172.16.20.99
}
Remplacez par votre IP du plan d'adressage.
Dans le fichier init-k8s.yaml
Au niveau de :
- name: Initialiser le cluster Kubernetes
ansible.builtin.command: kubeadm init --control-plane-endpoint "172.16.20.99:6443" --upload-certs --pod-network-cidr=192.168.0.0/16
when: not kube_cluster.stat.exists
Remplacez 172.16.20.99 par la VIP pour le control-plan.
Au niveau de :
- name: Installation Traefik
hosts: master[0]
become: true
tasks:
- name: Create a IPPool
kubernetes.core.k8s:
state: present
definition:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
namespace: metallb-system
name: ippool
spec:
addresses:
- 172.16.20.100/32
Remplacez par 172.16.20.100 par l'@IP pour l'Ingress Traefik.
Entrées DNS (hosts / server DNS)
Il faudra déclarer les entrées suivantes avec @IP de l'Ingress Traefik choisie :
monitoring.kube.lan A 172.16.20.100
prometheus.kube.lan A 172.16.20.100
Remplacez par 172.16.20.100 par l'@IP pour l'Ingress Traefik.
Inventaire ansible
Editer le fichier d'inventaire : inventory/inventaire.yaml
- Mettre à jour les @IP des noeuds
ansible_host: @IP - Mettre à jour l'utilisateur
ansible_user: user=> **Cet utilisateur doit pouvoir faire des commandessudosans mot de passe. Sinon ajouter-kou-Kqui permet de donner le mot de passe pour devenir sudoers. - Ajouter ou supprimer les hosts nécessaires.
Exécution
Copier la clé publique vers le bastion
Générer un couple de clé publique privé :
ssh-keygen -t rsa -b 2048 -> ENTER, ENTER, ENTER...
Copier la clé publique sur chaque noeud du cluster :
ssh-copi-id user@IP_NOEUD
ANSIBLE
Depuis bastion-ansible :
- SSH sur chaque VM cible (ajout du fingerprint SSH).
Pour lancer l'installation de Kubernetes (pas initialisation cluster):
ansible-playbook -i inventory/inventaire.yaml install-k8s.yml
Pour initialiser le cluster K8s :
ansible-playbook -i inventory/inventaire.yaml init-k8s.yaml
Il initialise le cluster, puis installe un pluging réseau (Calico), installe Traefik avec la configuration réseau. A ce niveau sur votre vm
ansible-bastionvous aurez le fichierKubeconfig-master-00(équivalent)
Pour installer la stack monitoring (Prometheus, Loki, Grafana)
ansible-playbook -i inventory/inventaire.yaml install-monitoring.yaml
Vérification
Il faudra vous connecter sur master-00 en root, puis exécuter :
kubectl get nodes
Sortie attendue :
master-00 Ready control-plane 2m29s v1.29.14
master-01 Ready control-plane 23s v1.29.14
master-02 Ready control-plane 21s v1.29.14
worker-00 Ready <none> 71s v1.29.14
worker-01 Ready <none> 72s v1.29.14
worker-02 Ready <none> 71s v1.29.14
Interraction avec le cluster
Faire les exports (si depuis la VM master-00):
export K8S_AUTH_KUBECONFIG=/root/.kube/config
Récupérer mot de passe Grafana (depuis master-00)
Le login est : admin
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
Grafana
Les URL de datatsources sont :
- prometheus: http://prometheus-server/
- Loki : http://loki:3100/
La récupération de l'information se fait avec la commande suivante :
kubectl get svc -n monitoring
- svc : service Kubernetes
- -n moniroting : Spécifique de récupérer les objets dans le namespace
monitoring
Prometheus récupération des données HORS-CLUSTER
Editer le fichier install-monitoring.yaml :
- name: Deploy latest version of Prometheus chart inside namespace and create it
kubernetes.core.helm:
name: prometheus
chart_ref: prometheus-community/prometheus
release_namespace: monitoring
create_namespace: true
values:
server:
persistentVolume:
enabled: false
serverFiles:
prometheus.yml:
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
## Below two files are DEPRECATED will be removed from this default values file
- /etc/config/rules
- /etc/config/alerts
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: prometheus-node-exporter-vm-deportee
static_configs:
- targets:
- 172.16.20.36:9100
La section values est le contenu du fichier YAML prometheus.yml.
Rejouer le playbook :
ansible-playbook -i inventory/inventaire.yaml install-monitoring.yaml
Ressource : stephane-robert.info : https://blog.stephane-robert.info/docs/observer/metriques/prometheus/
Bonus - Ajout d'un noeud dans le cluster
- Déclarer le/noeuds dans l'inventaire
inventory/inventaire.yaml(Un noeud ne peut être à la fois control-plan et worker) - Avoir exécuter le playbook
install-k8s.yamlsur le noeud - Jouer le playbook -
add-node-k8s.yaml
ànsible-playbook -i inventory/inventaire.yaml add-nodes-k8s.yaml
K9s - Terminal User Interface pour Kubernetes (exploration des objets Kubernetes)
L'installation est similaire à kubectl
Pour interragir avec le cluster en spécifiant le kubeconfig :
k9s --kubeconfig /chemin/vers/le/kubeconfig
https://enix.io/en/blog/k9s/
https://blog.stephane-robert.info/docs/conteneurs/orchestrateurs/outils/k9s/
Installation manuelle monitoring avec Dashboard déjà fait
Ne pas avoir exécuter le playbook : install-monitoring.yaml.
Accès kubectl (master-00 ou depuis le poste de travail avec le kubeconfig-master-00).
HELM doit être installer sur la machine où les commandes sont exécutées.
Ajouter le dépôt :
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
Créer le namespace et le définir comme contexte par défaut :
kubectl create ns monitoring
kubectl config set-context --current --namespace=monitoring
Installation via HELM :
helm install prometheus prometheus-community/kube-prometheus-stack
Créer une règle dans notre Ingress Traefik monitoring-ingress.yaml :
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana-ingress
namespace: monitoring
annotations:
kubernetes.io/ingress.class: traefik
spec:
rules:
- host: monitoring.kube.lan
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-grafana
port:
number: 80
Puis faire :
kubectl apply -f monitoring-ingress.yaml
Login : admin
Password : kubectl get secret grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
conclusion
En combinant Terraform et Ansible, nous avons posé les bases solides d’un cluster Kubernetes déployé de manière entièrement automatisée, reproductible et évolutive. Ce workflow DevOps permet de gagner un temps précieux tout en assurant une gestion claire et versionnée de l’infrastructure.
Mais ce n’est qu’un début. Pour rendre ce cluster véritablement prêt pour la production, plusieurs étapes restent à franchir. Il faudra notamment intégrer un système de stockage distribué, comme iSCSI pour un usage bloc, ou S3 (ou compatible) pour un stockage objet, selon les besoins des applications. Ensuite, la mise en place d’une stratégie de sauvegarde robuste avec Velero permettra d'assurer la résilience des données et des workloads. Enfin, un hardening de la sécurité s’imposera, en renforçant les configurations réseau, les politiques RBAC, et en activant le chiffrement des secrets.
Nous aborderons toutes ces étapes dans les prochains articles, pour faire évoluer ce cluster vers un environnement sécurisé, résilient et réellement prêt pour le monde réel.